- wenn Oliver einen Unterschied 32/16 zu 22.5/16 hört, ist dies nun ein Beweis dafür, dass er richtig hört, ein anderer jedoch nicht, welcher meint einen Unterschied 192/24 zu 44/16 auch blind wahrzunehmen? Hilft dabei eine Statistik-Tabelle von Olivers Hörtest?
- wenn feine Pegelunterschiede verantwortlich dafür sind, dass 192/24 besser klingt als 44/16, insbesonders wenn 192/24 etwas lauter sind, wieso gibt es nirgends einen Hinweis, dass 44/16 doch besser klingt als 192/24, weil es z.B. um 0.2 dB lauter ist? Man kann doch beliebig die Lautstärke anpassen.
- wenn denn schon bei Mikrofonaufnahmen ein Grundrauschen von -60 dB in praktisch jedem Raum vorhanden ist, wieso muss man dann eigentlich noch dithern? Nach der Erläuterung der Experten müsste doch das stets vorhandene Grundrauschen als Maskierung ausreichen, auch dann wenn dann auf eine geringere Bittiefe heruntergerechnet wird.
Nun, ein anderer Experte (Bob Katz) behauptet klar, unterschiedliche Ditheralgorithmen selbst bei 24 bit Bittiefe herauszuhören. Geht das überhaupt?
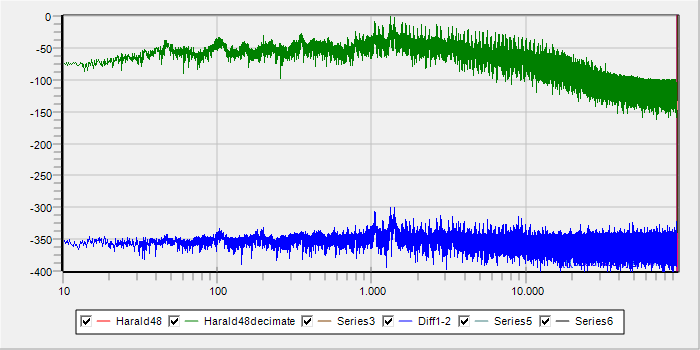
- wenn das Grundrauschen bei Haralds Aufnahme schon so hoch ist, wie stellt Truesound fest, dass da gedithert wurde? Kann man das doch hören?
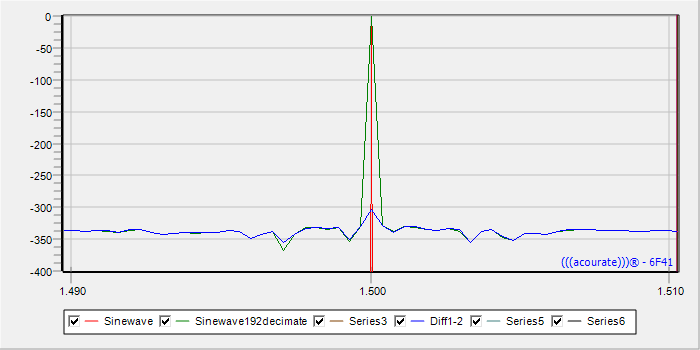
Ich habe mal folgenden Test gemacht, ausgehend von der Überlegung, dass ein geradzahliges Hochsampeln dadurch gemacht werden kann, dass man Nullsamples dazwischen einfügt und das Ganze durch einen sinc-Filter schickt. sin(x)/x ist nun = 1 für x=0. D.h. dass genaugenommen jedes reale Sample so erhalten bleiben müsste, wie es ist und dass dann nur die Zwischensamples bestmöglichst rekonstruiert werden.
Also, man nimmt den 192/24-Track und erzeugt nun mit jedem 4. Sample einen neuen Track = Downsampling. Wobei jedes Sample mit einem passenden Sample eines 48/24-Tracks korrespondiert. Dann kann man die Tracks subtrahieren und es verbleibt ein Rest, der den SRC-Fehler charakterisiert.
Mit den Beispiel-Dateien von Harald ergibt sich hiermit:
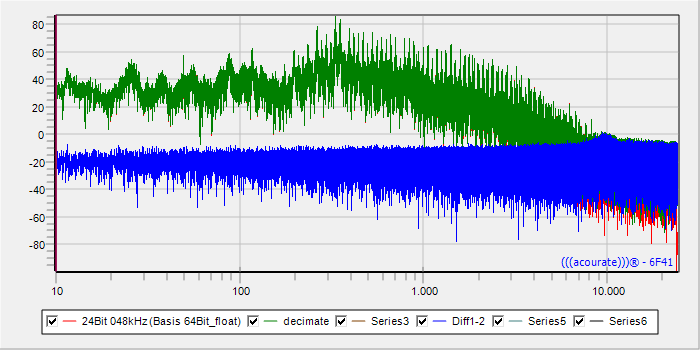
Das Bild zeigt eine FFT über die gesamte Tracklänge. Rot ist der originale Track, grün der von 192/24 auf 48/24 heruntergesampelte Track und blau die Differenz. Man erkennt, dass sich vor allem im hochfrequenten Bereich noch Unterschiede ergeben. Die blaue Differenz zeigt einen gleichmäßig niedrigen Rauschpegel, allerdings mit einem interessanten Buckel bei 10 kHz. Ursache unbekannt.
Nun hat ja Truesound ein "besseres" Resampling gemacht. Inkl. penibler Pegelanpassung. Das führt nun zu folgendem Bild:

Dabei zeigt die blaue Kurve ein Differenzverhalten das nun gar nicht mehr nur ein Rauschen enthält, sondern auch Musikbestandteile. Was nicht sein sollte und dürfte.
Die nähere Untersuchung ergibt, dass der pegelangepasste 48/24-Track von Truesound um 0.0243 dB zu laut ist. Das lässt sich korrigieren und es ergibt sich als neue Differenz:
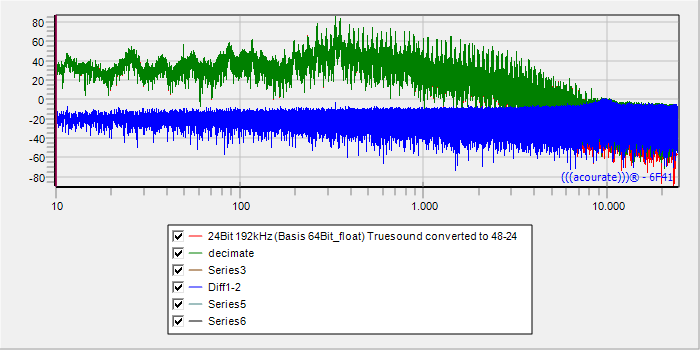
Somit haben wir letztlich ein Ergebnis welches dann wiederum mit Haralds Beispiel übereinstimmt. Hat da etwa ein Laie zufällig doch etwas richtig gemacht (bzw. einen funktionierenden SRC verwendet)?
Grüsse
Uli