angeregt durch Ulis Spektrogramme in diesem Thread habe ich mir nochmal meinen eigenen Beitrag in diesem Thread angesehen (der in der dortigen Diskussion wohl fast untergegangen ist). Ich möchte hier nochmal eine mit Bildern erweiterte Version posten.
Es soll mit einem richtigen Musikstück demonstriert werden, wozu dithering und noise shaping gut sind. In Ulis Thread geht es darum, ein Signal mit sehr niedrigem Pegel abzuspielen und wieder zu digitalisieren. Was ich hier vormache spielt nur im Digitalen, deshalb in einem separaten Thread.
Dies kann jeder nachmachen, der 'SOX' und 'Audacity' oder äquivalente Programme hat.
Hier ist ein Musikstück in der Datei data.wav ("Sketches" mit Paul Motion (Schlagzeug, meist Becken), Joe Lovano (Saxophon) und Bill Frisell (E-Gitarre)) mit 44100 16-Bit-Samples pro Sekunde, jedes Sample wird also durch eine ganze Zahl im Bereich −32768 bis 32767 dargestellt. In 'audacity' sieht das graphisch so aus:
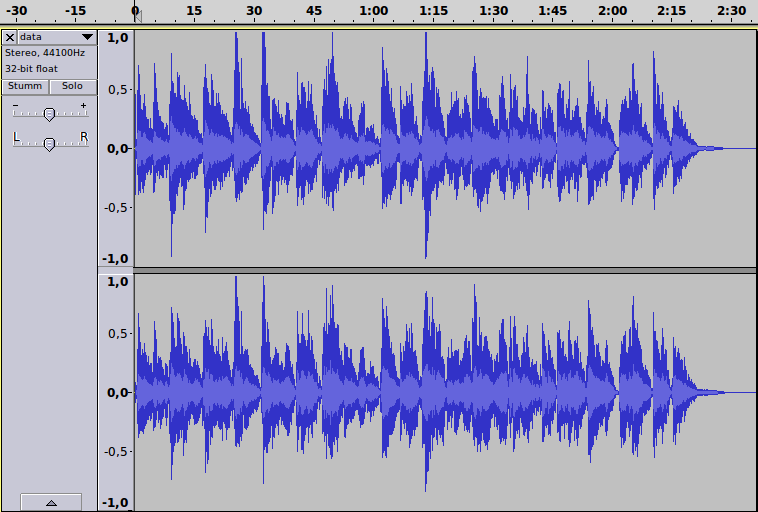
und in der Spektralansicht wird gezeigt, welche Frequenzbereiche jeweils dominieren:
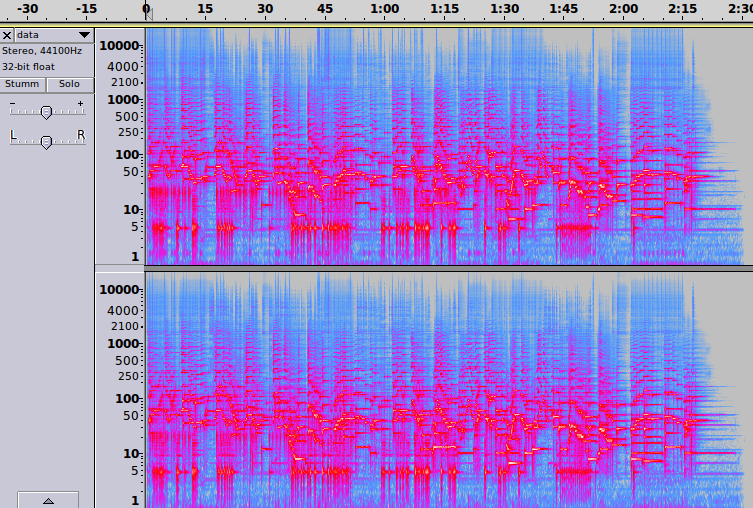
Mit dieser Kommandozeile
Code: Alles auswählen
sox data.wav -t raw -e float -b 64 - | sox -t raw -c 2 -r 44100 -e float -b 64 - -t raw -c 2 -r 44100 -e float -b 64 - vol 0.000025 | sox -V -D -t raw -c 2 -r 44100 -e float -b 64 - -t raw -c 2 -r 44100 -e signed -b 16 - |sox -t raw -c 2 -r 44100 -e signed -b 16 - testbad.wav vol 512.0
- dann die Lautstärke um den Faktor 40000 verringert (in der ursprünglichen 16 Bit Darstellung wären jetzt alle Samples 0, aber durch die genaue Fließkommadarstellung ist hier noch alle Information vorhanden).
- dann werden die Samples wieder in ganze Zahlen mit 16Bit umgerechnet (mathematisch: mit 32768 multipliziert und zur nächsten ganzen Zahl gerundet)
- dann wird die Lautstärke um den Faktor 512 erhöht (nur damit man was sieht und hört)
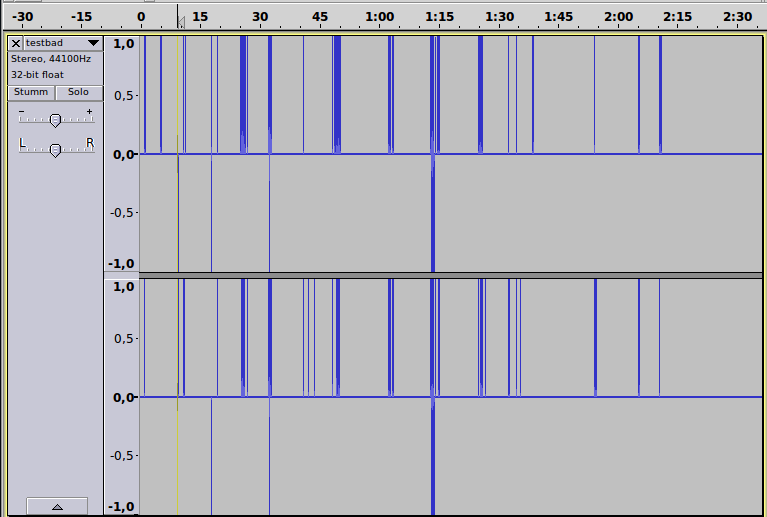
und in der Spektralansicht:
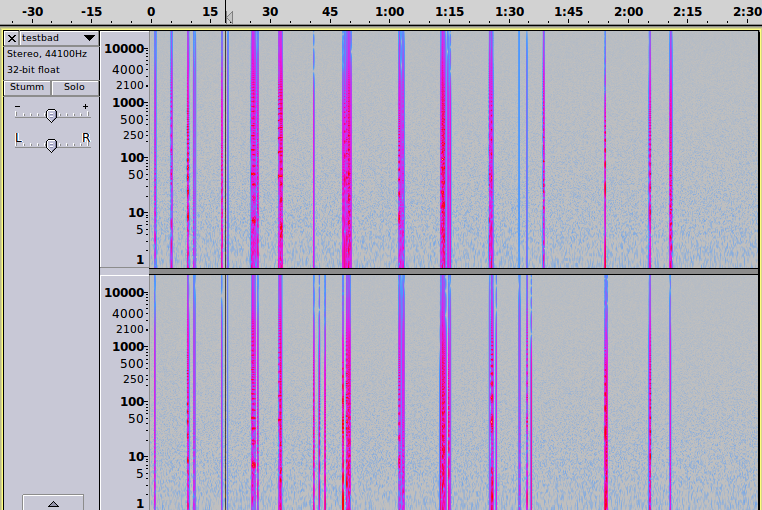
Anhören ist grausam, meist Stille und scheußliche Klicks; die brutale Rundung auf 16 Bit Ganzzahlen hat die Musikdatei unwiederbringlich zerstört!
Die folgende Kommandozeile
Code: Alles auswählen
sox data.wav -t raw -e float -b 64 - | sox -t raw -c 2 -r 44100 -e float -b 64 - -t raw -c 2 -r 44100 -e float -b 64 - vol 0.000025 | sox -V -D -t raw -c 2 -r 44100 -e float -b 64 - -t raw -c 2 -r 44100 -e signed -b 16 - dither |sox -t raw -c 2 -r 44100 -e signed -b 16 - test.wav vol 512.0
Hm, und was soll das retten? Sehen wir wieder die graphische Darstellung an:
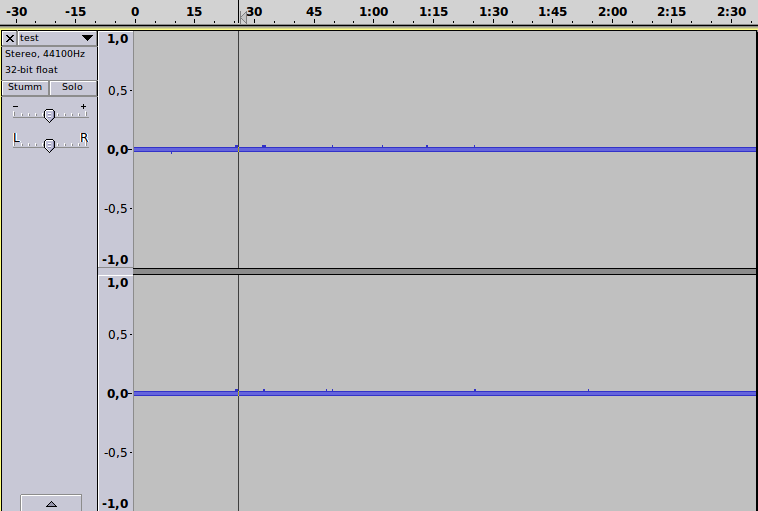
Und mit höherer Lautstärke:

mit einem kleinen Ausschnitt:
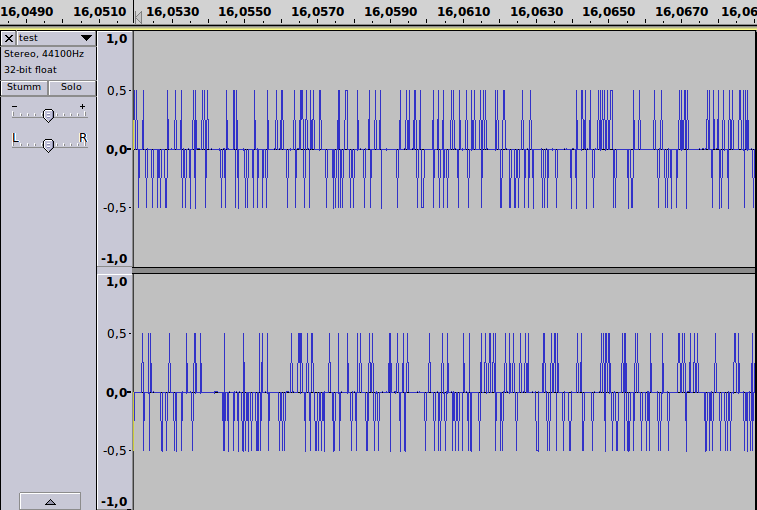
und Spektralansicht:
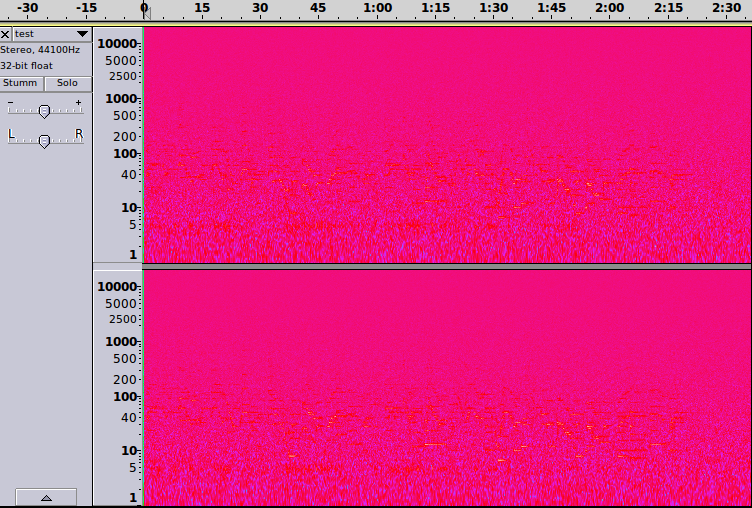
Das sieht nach lautem Rauschen aus. Das ist es auch, aber wenn man genau hinsieht, schimmert in der Spektralansicht auch etwas vom Original durch. Und das bestätigen die Ohren, beim Abspielen ist ein lautes Rauschen zu hören und darunter ist das ursprüngliche Stück wieder zu erkennen.
Wie kann das sein? Die grobe Idee ist, dass ein Fließkommawert wie zum Beispiel 0.1 durch die Addition einer Zufallszahl bei der Rundung nicht immer zu einer 0 führt, sondern manchmal auch zu einer 1, und zwar so, dass von 100 Samples mit dem Wert 0.1 ungefähr 10 Mal bei der Rundung 1 und sonst 0 herauskommt, also im "Mittel" etwa 0.1. Jedes einzelne Sample wird dadurch nur noch ungenauer repräsentiert. Beim Hören und bei der Berechung der Spektralansicht wird aber nicht Sample für Sample separat verarbeitet, sondern es findet gerade eine Mittelung über kurze Zeitintervalle statt, um das Frequenzspektrum zu analysieren. Durch das Dithering wird im Ergebnis also zusätzliche statistische Information über das Originalsignal kodiert, und zwar gut genug, damit wir das Stück wiedererkennen können. Ganz wichtig ist an dieser Stelle, dass vor der Rundung (also Rückübersetzung in 16 Bit Zahlen) unsere Samples eine höhere Genauigkeit haben. Wenn das nicht der Fall wäre, gäbe es ja gar nichts, was das Dithering statistisch kodieren könnte und es würde nur ein leises zusätzliches Rauschen erzeugt.
Zum Schluss noch das noise shaping. Das geht mit dieser Kommandozeile:
Code: Alles auswählen
sox data.wav -t raw -e float -b 64 - | sox -t raw -c 2 -r 44100 -e float -b 64 - -t raw -c 2 -r 44100 -e float -b 64 - vol 0.000025 | sox -V -D -t raw -c 2 -r 44100 -e float -b 64 - -t raw -c 2 -r 44100 -e signed -b 16 - dither -f high-shibata |sox -t raw -c 2 -r 44100 -e signed -b 16 - testgood.wav vol 512.0
Das Ergebnis in der Datei testgood.wav sieht nun so aus:
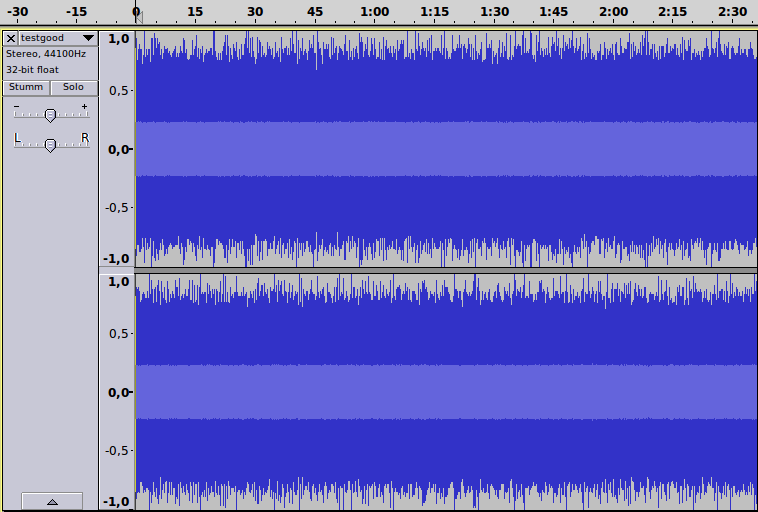
Beim Anhören ist nun ziemlich leise gut die Originalmusik zu erkennen. Geht das auch lauter? Es zeigt sich, dass mit einem steilen Tiefpassfilter bei 13 kHz (darüber höre ich eh nichts) folgendes übrig bleibt:
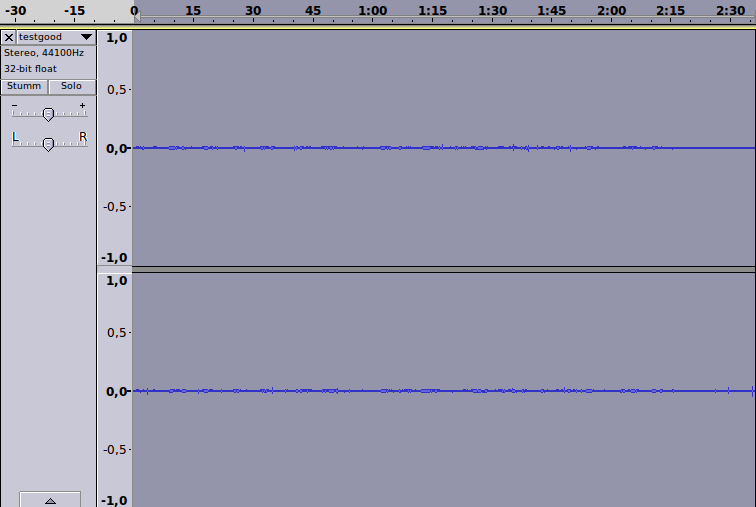
Das kann dann auch lauter gemacht werden:
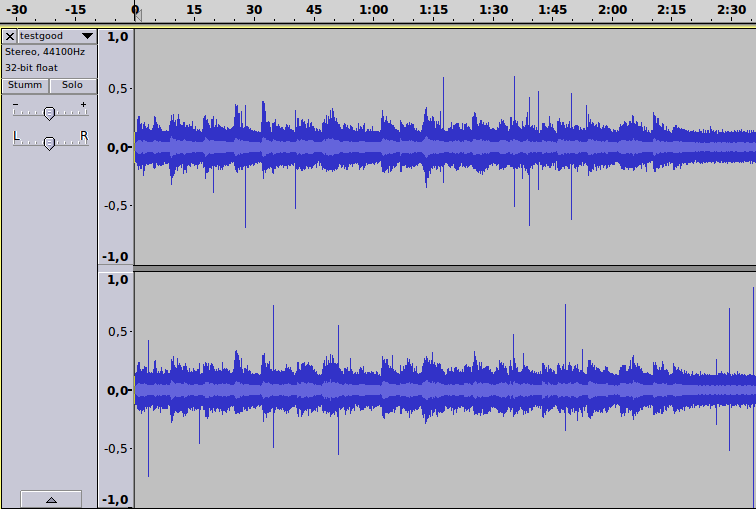
und in der Spektralansicht:
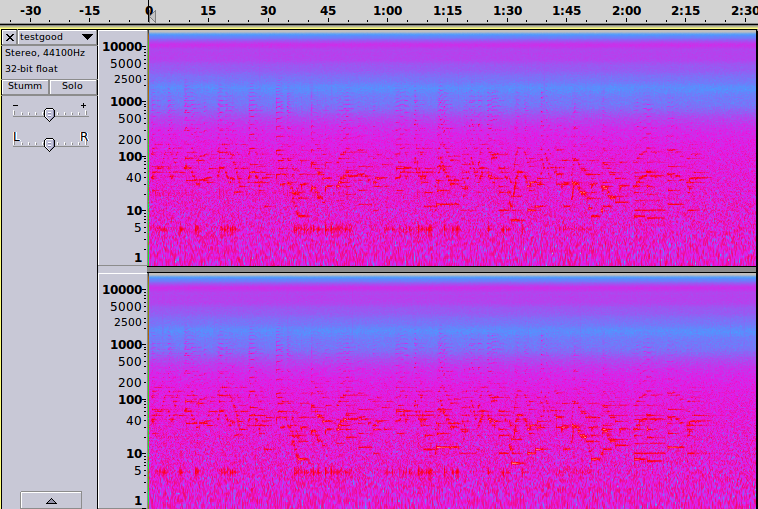
ist recht viel von der Originaldatei zu erkennen.
Beim Anhören sind jetzt die langen eingeschwungenen Töne des Saxophons und der E-Gitarre wieder gut zu erkennen. Transienten, also sehr kurze Impulse, insbesondere die Schlagzeugbecken, sind allerdings nicht mehr auszumachen. Das passt ganz gut zu der Statistik-Erklärung von oben.
Also, ich war verblüfft, als ich das erste Mal gesehen und gehört habe, wieviel von der Musik, deren Samples durch die Lautstärkeveringerung eine kleinere Amplitude als das kleinste Bit haben, noch rekonstruiert werden kann. Und ich finde es interessant, wie ähnlich die graphische Mustererkennung in der Spektralansicht der Mustererkennung beim Hören zu sein scheint.
Die Audiodateien will ich hier nicht verlinken, damit es keine Copyright-Probleme gibt. (Wer sox hat, kann das ja auch leicht nachmachen. Und es gibt PN).
Viele Grüße,
Frank
